2026 年 6 月深圳前端工作行情
给正在找工作的朋友一些参考。 🔧技术栈 📋笔试要点 算法题类 传统企业考算法题的比较多(前端的算法这块儿本就是 […]
给正在找工作的朋友一些参考。 🔧技术栈 📋笔试要点 算法题类 传统企业考算法题的比较多(前端的算法这块儿本就是 […]
法国达索公司开发的 SOLIDWORKS 软件售价 3 万人民币一套,至今仍是制造业中非常关键的 CAD/CA […]
问题表现 在 SELinux + Systemd 的 Linux 系统上,用 PM2 管理部署 Node.js […]
暗黑破坏神 4 必须连接暴雪的战网服务器才能启动。 国内的 Steam 版暗黑 4 玩家,就需要手动换区。有两 […]
Steam Deck 默认用户名为 deck 没有密码,正常安装运行游戏也不需要密码。 但是如果你需要在桌面模 […]
你可能已经写了很多年 ES Module (ESM) 语法的代码。比如: 但实际上,大部分 ESM 语法代码是 […]
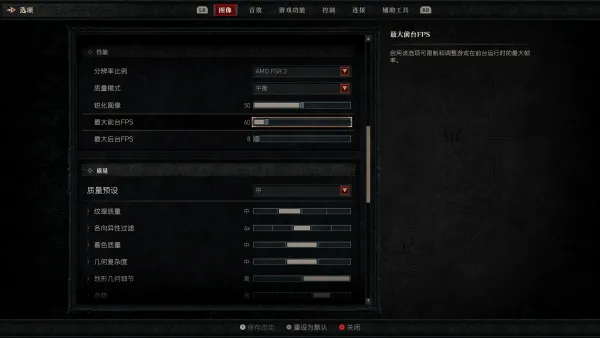
由于暴雪的游戏引擎设计缺陷,导致 GPU 满载的情况下会持续显存泄漏,帧率逐步下降到个位数,直至完全不可玩。最 […]
2023 年 12 月,React 19.0.0 终于发布。但是经过一些实验之后,我决定暂缓升级我的 Reac […]
被墙的不严重的网站,通常是被 DNS 污染了。这种网站用 Hosts 方法就很容易实现科学上网。Hosts 即 […]
威能 项链:统御秘术(项链) 统御秘术威能附在装备上可以增加 2 个骷髅战士和 2 个骷髅法师。而附加在项链可 […]