原生 Linux 游戏的现状
虽然大部分 Windows 游戏可以通过 Wine/Proton 在 Linux 上运行,但是运行效率损耗导致 […]
虽然大部分 Windows 游戏可以通过 Wine/Proton 在 Linux 上运行,但是运行效率损耗导致 […]
来自小欢欢的旅行计划~~~ 申根签证 包含国家 已经刷过的: 还没刷过的: 准备材料 注意事项: 网上提交 欧 […]
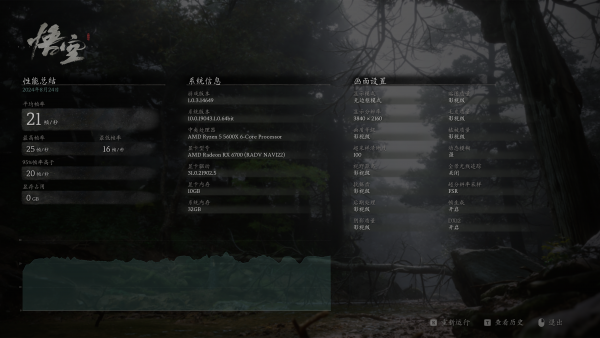
采用《黑神话:悟空性能测试工具》测试。 CPU:AMD Ryzen R5 5600X RAM:4*8GB DD […]
垂直同步(V-Sync)是为了解决 GPU 输出帧率与显示器刷新率不一致而导致的画面撕裂问题而诞生的技术。它的 […]
NPS 和 XCI 最主要的区别在于来源的数据载体。 XCI 文件是从 Switch 实体卡带导出的。一些 S […]
以下都是我个人玩过的,按个人评分排序。有些知名游戏没列出来完全是因为本人没玩过或者没兴趣。 星露谷物语 ⭐⭐⭐ […]
新买的 Xbox One/Series 手柄通过蓝牙连接 Linux 是无法正常使用的,需要一些操作。但是网上 […]
TL;DR: 事件经过 axios 1.7 于2024年五月底发布。这个版本的一个重大变化是新增了基于 fet […]
用了不到半年,滚轮轴断了!拆开后发现滚轮轴的受力点最细的地方连 1mm 都不到(设计缺陷),而且材质偏脆(材料 […]
最近换手机了,发现我之前用的 OTP/2FA 软件 andOTP 已经停止更新了。于是开始寻找一些替代品。以下 […]