如何优化 INP
INP 是 Interaction to Next Paint 的缩写,指的是从用户交互(通常是点击和键盘输入 […]
INP 是 Interaction to Next Paint 的缩写,指的是从用户交互(通常是点击和键盘输入 […]
标准 这里定义的前端构建工具需要符合以下条件: 生产可用 这里定义的生产可用条件: Vite 4 Vite 基 […]
开发者通常在最新的浏览器上进行开发,以使用最新的 JavaScript 语法,浏览器接口,让工作更有效率,代码 […]
2022 年,Webpack + Babel + Terser 仍然是前端项目构建工具的主流,广泛用于各种生产 […]
众所周知,计算机以二进制存储数字,而真实世界中用十进制表示数字。二进制和十进制的差异可以用一个乍看非常怪异的例 […]
字体单位 px 依旧是最全面的选择,尤其是重交互的网站: 能够做到设计稿的像素级还原。 用户体验统一,变量少, […]
前端技术发展很快,有些技术如常青树,有些则已日渐式微。不断涌现的新技术,有的是真创新,有的是换汤不换药。本文希 […]
做一个应用程序有非常多不同的技术选择。使用 Web 技术既可以用做小的开发成本做出跨平台的应用,但是性能和功能 […]
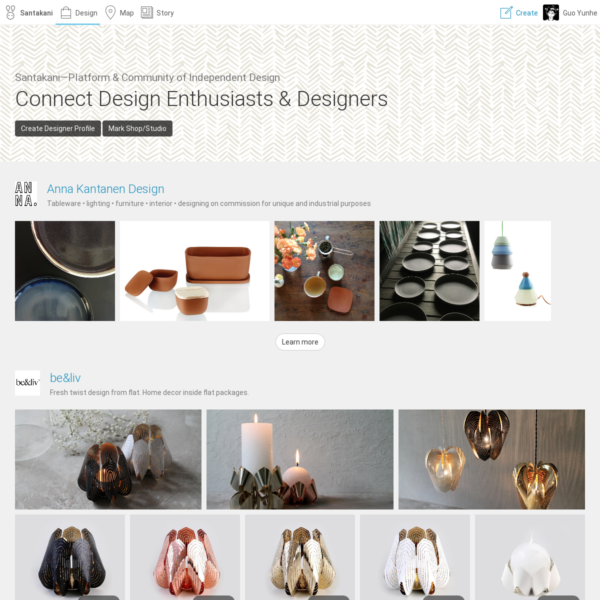
本周做了 Santakani 网站首页的改版。 对比旧版,新版将首页/设计/设计师三个列表页面合并为全新的首页 […]
网络验证码技术虽然是外国人发明的,但却在天朝泛滥成灾。 我们有那么多同学去做 UX ,花了那么多心思给用户提供 […]